Data enrichment: build connections and unlock insights
Enhancing data makes exponential increases to its value. Add new intelligence to get data that’s so much more than the sum of its parts.
Enhancing data makes exponential increases to its value. Add new intelligence to get data that’s so much more than the sum of its parts.

Enriching data makes it more applicable in more use cases, and increases the value of data you already have.
Build master data records on common identifiers and get robust products that accelerate time-to-insights.
In data, 1+1=11. The insights you can generate from enriched data are deeper, smarter, and higher quality.

Enrich data on its way into the catalog to make light work of heavy tasks. Deliver project-ready data products to every individual and team in your organization.

There are unique solutions for every stage in the data lifecycle — and massive inefficiencies. Adopt best practices and consolidate your view with a data management platform.
Centralizing your data operations means lowering your risk of errors and data leakage. Better data and better practices lead to better results every time.
Consider your entire data pipeline; shouldn’t it be easier? A data fabric supports data enrichment alongside discovery, efficiency, delivery, and compliance.

We’ve got you covered. Our catalog platform provides role-based access controls and secure, auditable sharing to support governance best practices.
Govern Data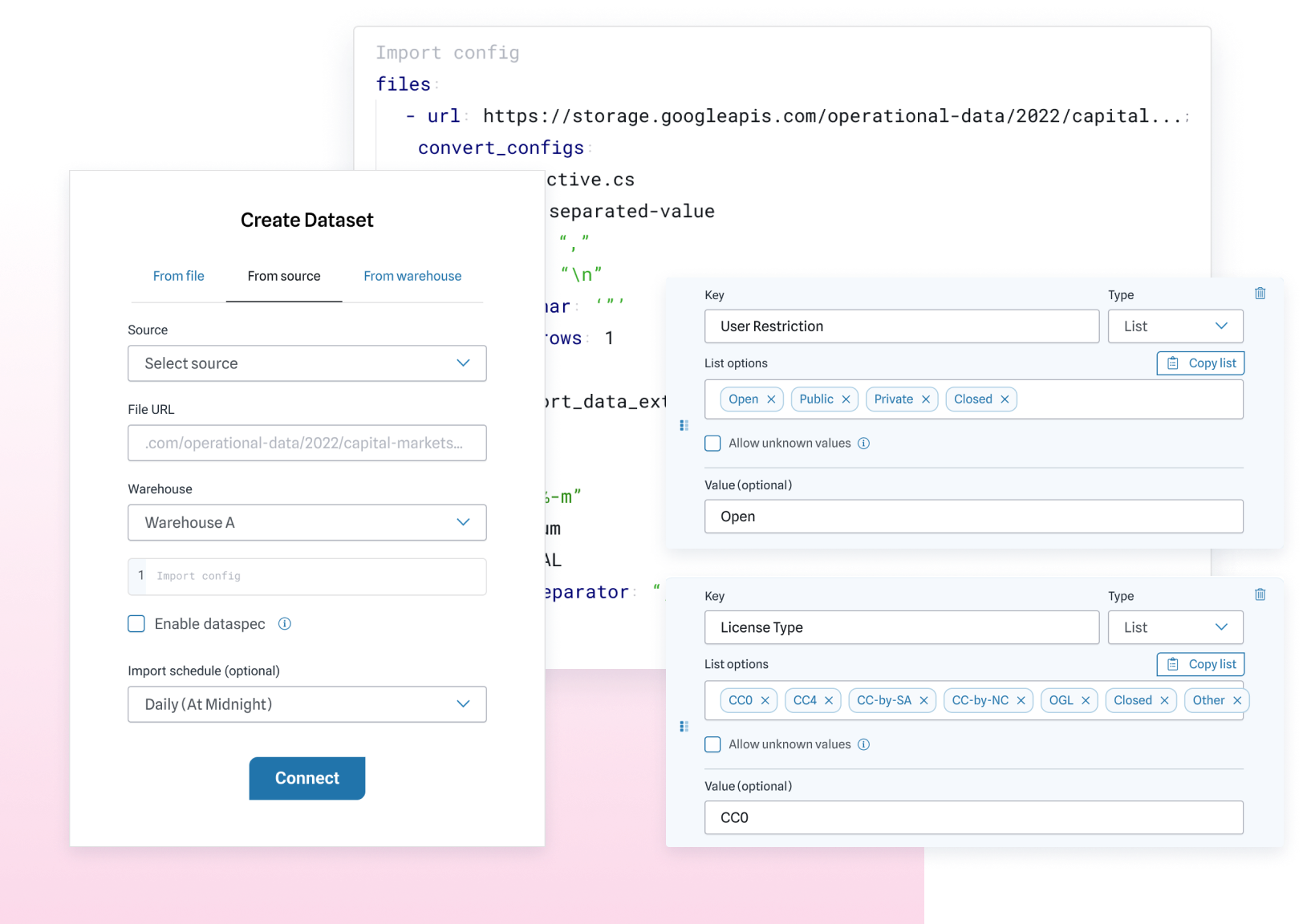
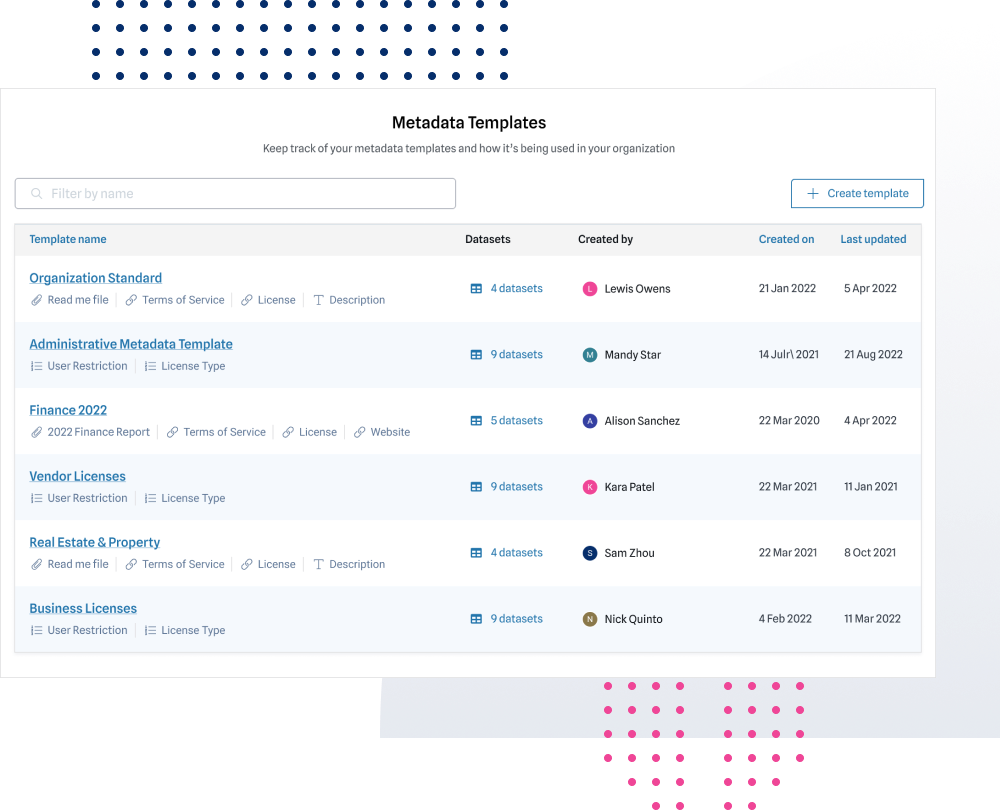
ThinkData Works improves data quality and enhances intelligence.
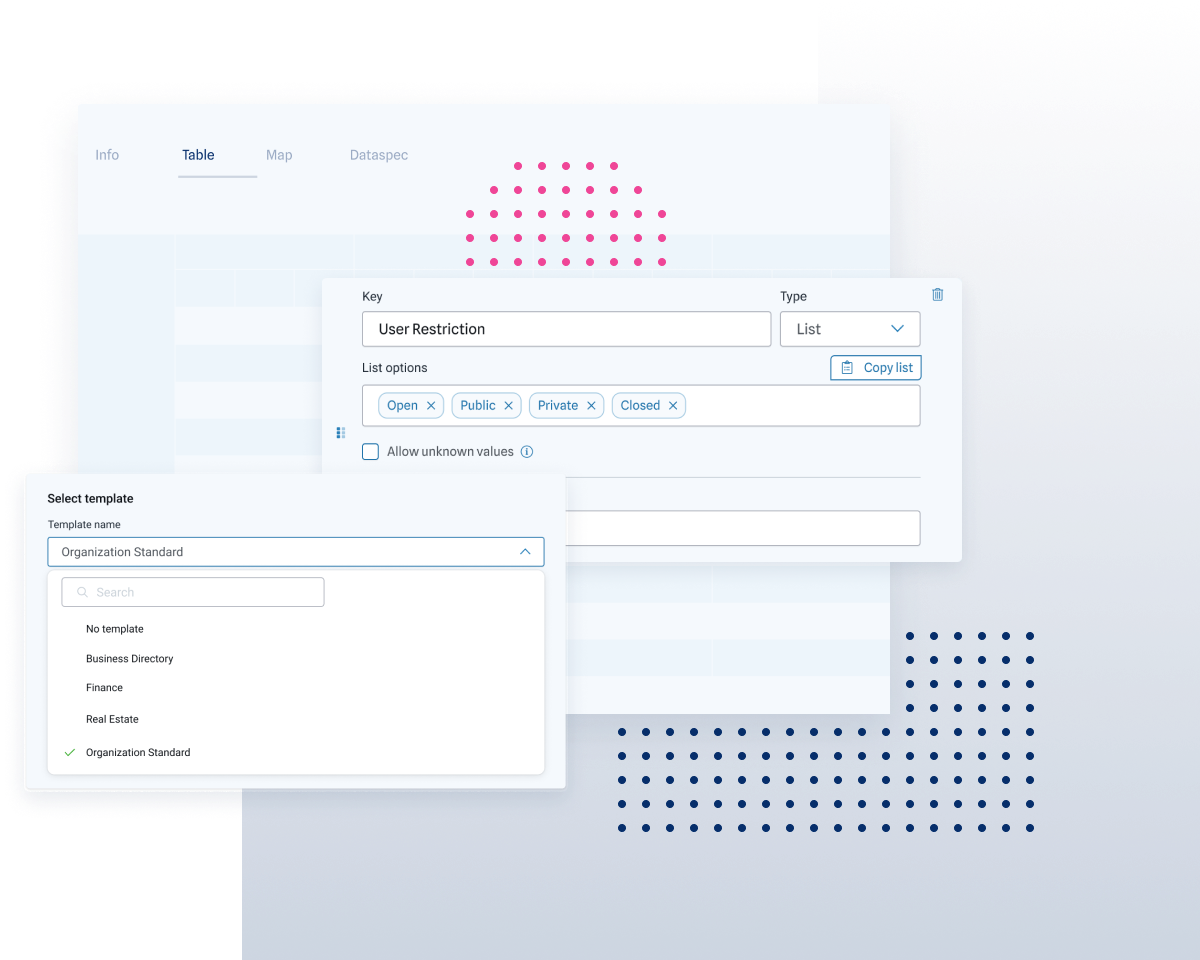
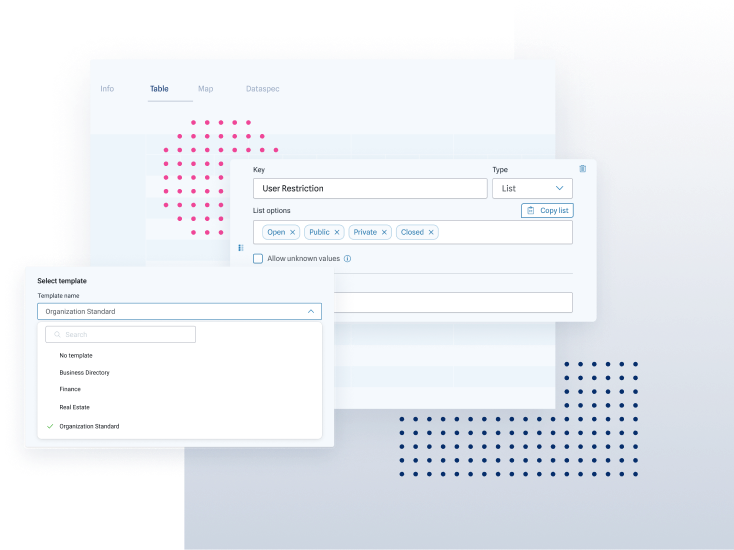
Improve data quality the instant it’s in the ThinkData Works Platform.
A powerful machine learning solution to the complexity of record linkage
Our team is here to help build custom solutions to meet your needs.
We are a part of your team, and we want your projects to be successful, fast. Make the best use of all of your data resources.
New sources add new complexity — so let us handle it. Start using data from anywhere to get holistic, actionable insights.

Some of the largest consulting, pharmaceutical, and financial institutions in the world depend on ThinkData Works.
Data enrichment is just one way that ThinkData Works makes every piece of data more valuable to your organization. Reach out to us today to book a demo.