
Airtight audit trail
Bring transparency to data sharing and access on a central platform connecting teams, data, and usage.
Having full control and awareness of your data is critical. Build structure and oversight that make compliance a piece of cake.
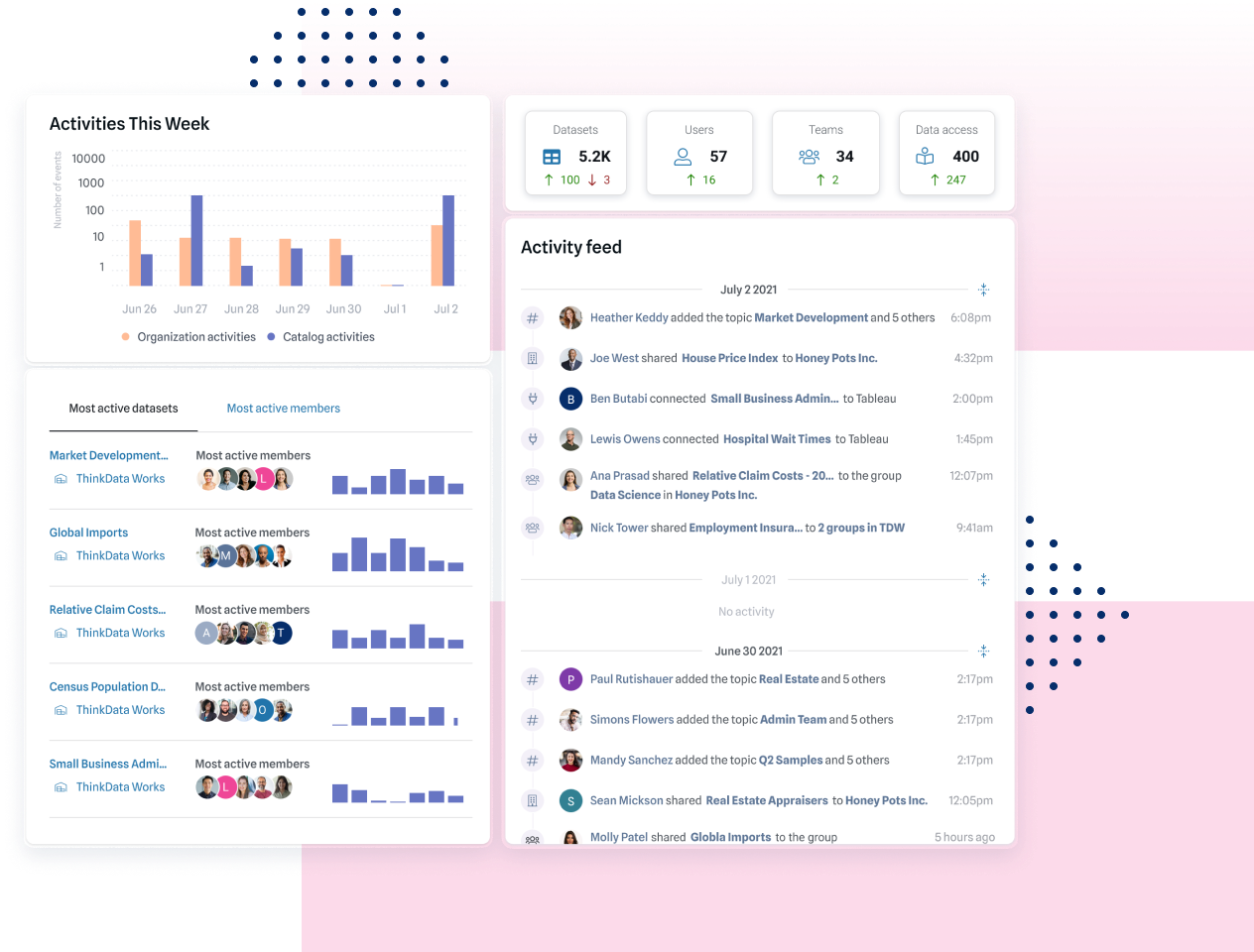

Bring transparency to data sharing and access on a central platform connecting teams, data, and usage.

With so many moving parts, it can be hard to ensure data consistency and quality. Data health monitoring tools deliver full confidence.

See granular details about what data is being used, and how. A connected dashboard gives you direct line-of-sight into data access.

A strong data governance framework fuels innovation. See how your people and technology can come together to support your growth.
Data-driven companies depend on:
Model your org structure with role-based access controls and teams.
Fuel smarter collaboration on a secure, central platform.
Inform your strategy with metadata around data usage, access, and management.
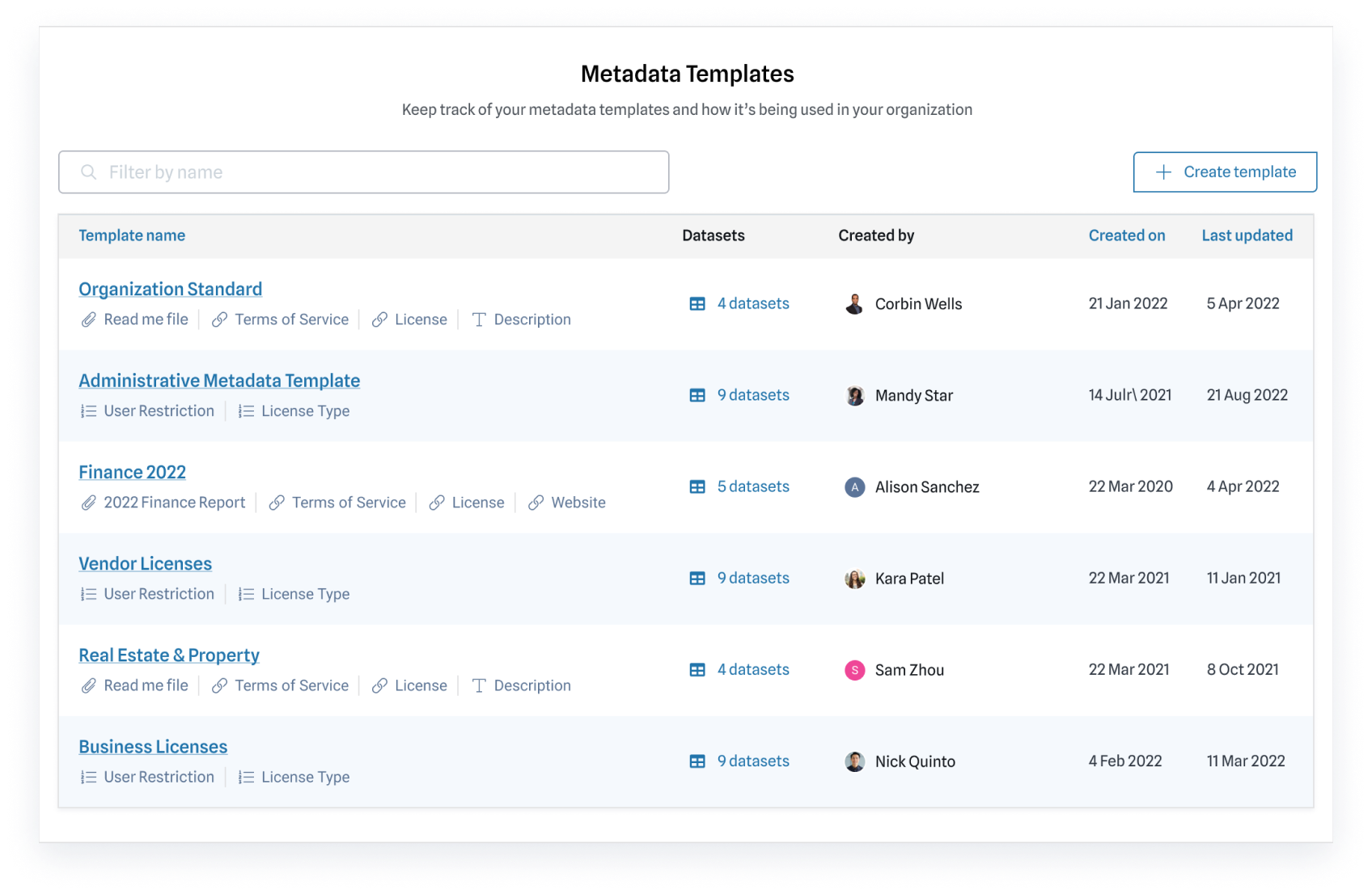
With a strong foundation in place, you can accelerate data-driven innovation. Get in touch to see what else our end-to-end platform can do for you.
